Meet Radio-Canada.ca, Canada’s French national news website. Essentially the cheap copy of CBC.ca, the sexy English counterpart. Being one of ~7.5 million francophones of Quebec, I’ve used this site a lot, and it’s been frustrating. I’m not sure if it’s actually the worst national news website in the world, but if not it must be close. This site has a bad URL, it’s painfully slow, extremely buggy, insecure and uses outdated technology. Don’t believe me? I decided to poke around for about an hour :
1. www.radio-canada.ca
look at this URL, just look at it. Now, R-C also controls national radio, and every time they spell out the URL out loud I choke on my coffee and die a little bit inside. It is that hard to get a shorter, hyphen-less URL? Please? (EDIT : I found one! see “bonus” section at the end!)
2. This site is SLOW.
Here’s a screenshot of the nextwork panel open from Chrome’s developer tools :
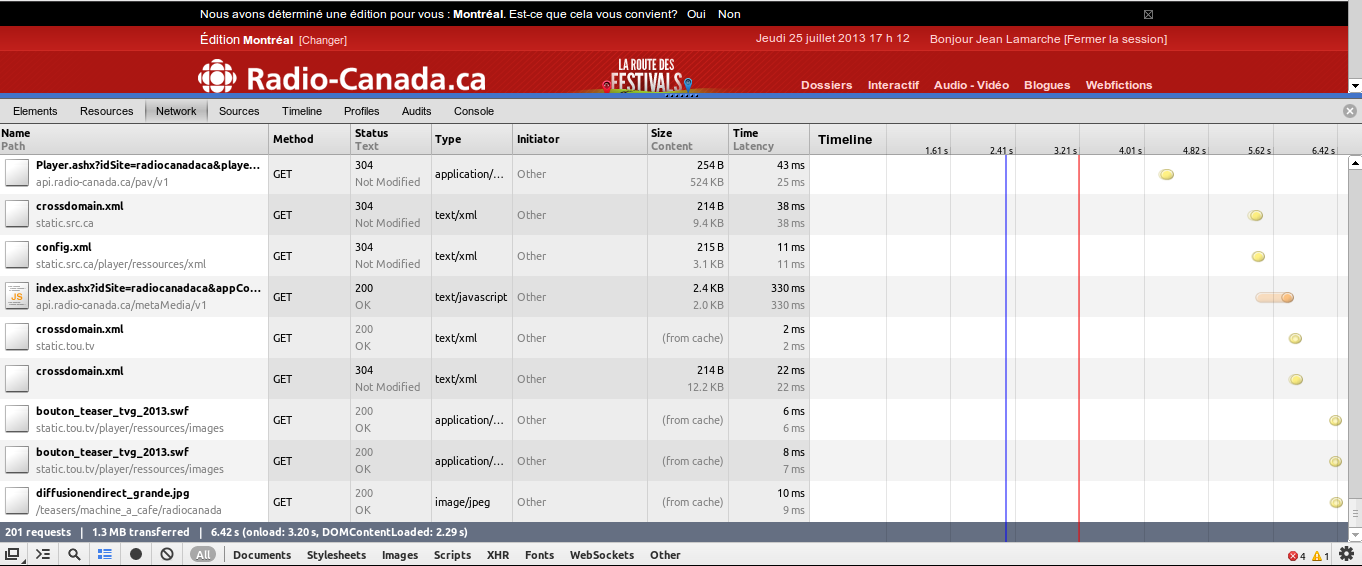
- 6.42 seconds! Usually my initial page load is 10-15 seconds.
- 201 requests (!!!)
- 1.3 MB transferred (!!!)
As if this wasn’t enough, have a look at this screenshot from Firefox’s debug pane :
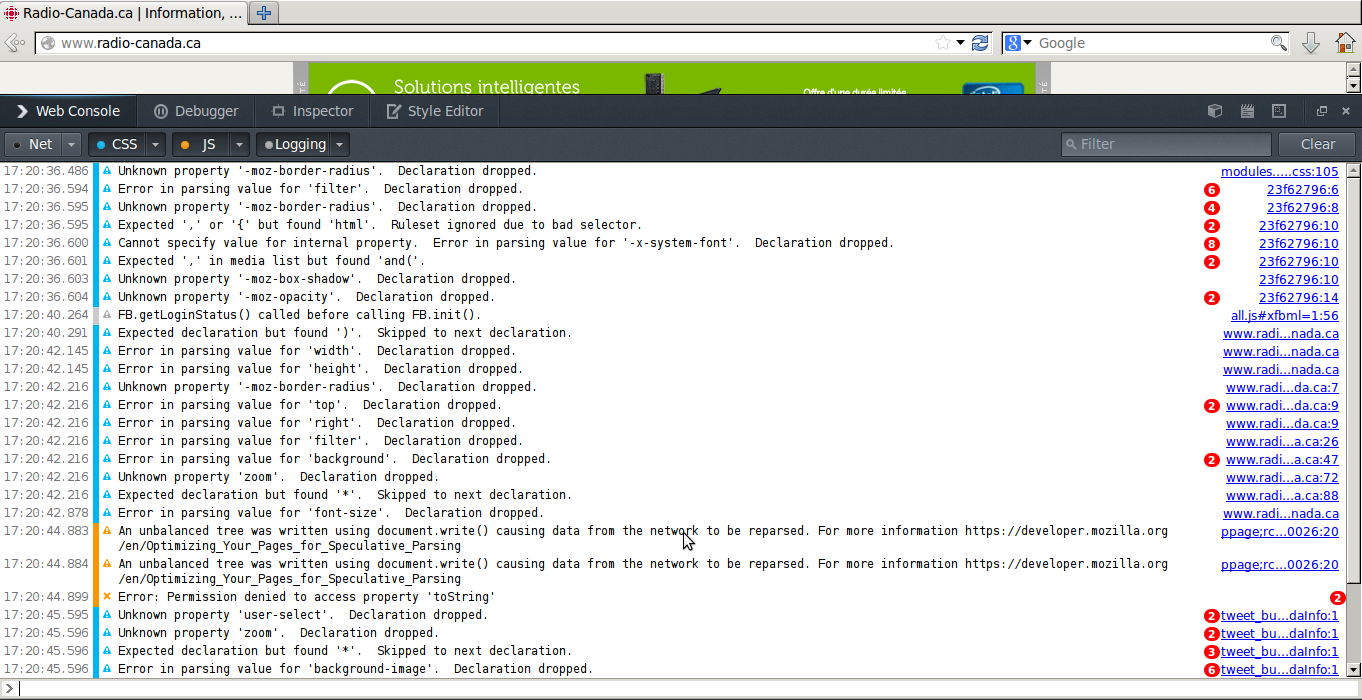
There are more JS errors in there than the scrollbar can show me. Seriously?
- I counted over 30 JS files, even someone who has been coding for 115 days knows that you have to condense all of those into a single file, avoiding 30+ requests!
- There are probably over 100+ images in that list (image sprites, maybe?)
- The rest of the files are HTML, JSON, SWF and other random files thrown in there.
- I’m pretty sure they could cut down the request count by ~80%, if they even tried.
All these things slow the site down to a crawl. But as if it wasn’t enough, R-C loves to use 3rd-party scripts to engage their readers! A quick list of SOME of the script files downloaded :
- scorecardresearch
- jquery (on google code’s repos)
- facebook.com (multiple)
- tou.tv
- googleadservices.com
- ping.chartbeat.net
- twitter.com
- g+
Why not wait until I actually click an article before throwing all this crap at my browser?
Even google’s PageSpeed scrore (77) page make this site look like it was hosted on geocities (or neocities now?). Check out the list of redirects! :
http://altfarm.mediaplex.com/.../12308-180242-27534-0?...
http://mp.apmebf.com/.../12308-180242-27534-0?...
http://altfarm.mediaplex.com/.../12308-180242-27534-0?...
http://img.mediaplex.com/.../1662053_119543_CA_SM_NA_FY14Q2_W13-OA...?...
http://altfarm.mediaplex.com/.../12308-180242-27534-1?...
http://mp.apmebf.com/.../12308-180242-27534-1?...
http://altfarm.mediaplex.com/.../12308-180242-27534-1?...
http://img.mediaplex.com/.../1662055_119543_CA_SM_NA_FY14Q2_W13-OA...?...
http://b.scorecardresearch.com/b?...
http://b.scorecardresearch.com/b2?...
http://radiocanada.122.2o7.net/.../s51798515080008?...
http://radiocanada.122.2o7.net/.../s51798515080008?...
http://sitelife.radio-canada.ca/ver1.0/Direct/DirectProxy
http://sitelife.radio-canada.ca/.../directproxyfast.js
http://www.google.com/pagead/drt/ui
https://googleads.g.doubleclick.net/.../si?... |
Mental! And none of the static images have an expiry header! (100+)
3. Article comments
- Comments are nested, but only 1 level deep. So if you feel like conversing with someone, forget it.
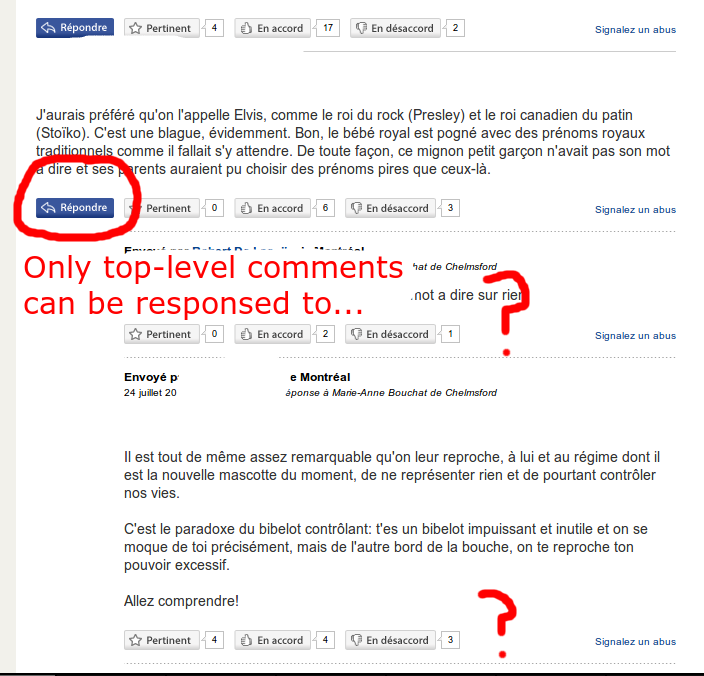
- They are posted, manually reviews 1 by 1, then approved. Comments can be arbitrarily discarded if R-C doesn’t feel like publishig them.
- Anonymous comments are not allowed, you MUST sign up through their crappy portal.
- CBC.ca do not have any of these issues – you can post anonymously, comments appear instantly (not 1h after posting them cause the guy reviewing it on taking his lunch break), and you can reply to replies! C’mon R-C.
- I won’t start with the quality of the comments, but let’s say it makes Youtube’s comment section look like a Shakespearean novel. At least CBC’s average comment is not that much better…
4. Security
I’m NOT a security professional, but I’m pretty sure this site is messed up.
1. insecure API:
Browse some more through console URLs…OH! “api.radio-canada.ca”, looks like they have an API (at least internal?), let’s click it!
- http://api.radio-canada.ca/pluck/ShowComments.aspx?articleId=ghtml-624483&numberofcomments=10000&userId=650736&displayPage=1&sorting=descending&type=&ts=1374712883795
- Looks like a GET, with no AUTH whatsoever. Public data I assume?
- numberofcomments=100? 1000? 2000? yes this works
- Full comment objects! Let’s look at a little piece more closely…
{
"Key": "ghtml-624610",
"ObjectType": "Models.External.ExternalResourceKey"
}, "ScoreCount": 0,
"AbsoluteScore": 0,
"DeltaScore": 0,
"PositiveScore": 0,
"PositiveCount": 0,
"NegativeScore": 0,
"NegativeCount": 0,
"CurrentUserHasScored": false,
"CurrentUserScore": 0,
"ObjectType": "Models.Reactions.ItemScore"
}],
"ObjectType": "Models.Reactions.Comment"
},
{
"CommentKey": {
"Key": "CommentKey:d7ce4130-6ff5-417d-97fa-cce2609c2a1f",
"ObjectType": "Models.Reactions.CommentKey"
},
"Owner": {
"Age": "",
"Sex": "None",
"AboutMe": "",
"Location": "",
"ExtendedProfile": [{
"Key": "Username",
"Value": "nostalgie1944",
"ObjectType": "Models.Common.SiteLifeKeyValuePair"
}, {
"Key": "First Name",
"Value": "Aline",
"ObjectType": "Models.Common.SiteLifeKeyValuePair"
}, {
"Key": "Last Name",
"Value": "Morin",
"ObjectType": "Models.Common.SiteLifeKeyValuePair"
}, {
"Key": "Province",
"Value": "Québec",
"ObjectType": "Models.Common.SiteLifeKeyValuePair"
}, {
"Key": "City",
"Value": "Ferme-Neuve",
"ObjectType": "Models.Common.SiteLifeKeyValuePair"
}, {
"Key": "u",
"Value": "394173",
"ObjectType": "Models.Common.SiteLifeKeyValuePair"
}],
"CustomAnswers": [],
"NumberOfMessages": 0,
"NumberOfFriends": 0,
"NumberOfPendingFriends": 0,
"NumberOfComments": 317,
"MessagesOpenToEveryone": false,
"PersonaPrivacyMode": 0,
"DateOfBirth": "\/Date(-62135578800000)\/",
"CommentsTabVisible": true,
"PhotosTabVisible": true,
"IsEmailNotificationsEnabled": true,
"SelectedStyleId": "",
"Signature": null,
"AwardStatus": {
"Badges": [],
"LeaderboardRankings": [],
"Activities": [],
"ObjectType": "Models.PointsAndBadging.AwardStatus"
},
"AbuseCounts": {
"AbuseReportCount": 0,
"CurrentUserHasReportedAbuse": false,
"ContentIsStandardAbuse": true,
"ContentExceedsAbuseThreshold": false,
"ObjectType": "Models.Moderation.AbuseCount"
},
"RecommendationCounts": {
"NumberOfRecommendations": 0,
"CurrentUserHasRecommended": false,
"ObjectType": "Models.Reactions.RecommendationCount"
},
"ImageId": "00000000-0000-0000-0000-000000000000",
"IsAnonymous": false,
"AvatarPhotoUrl": "http://sitelife.radio-canada.ca/ver1.0/Content/images/no-user-image.gif",
"AvatarPhotoID": "00000000-0000-0000-0000-000000000000",
"UserKey": {
"Key": "394173",
"ObjectType": "Models.Users.UserKey"
} |
- Interesting. So regardless if you check the “J’accepte que mes nom(s) et prénom(s) soient publiés” (I agree that my firstname and lastname are published) box, you can see every commenter’s firstname, lastname, NumberOfFriends, NumberOfComments, AbuseReportCount, city, user id – just to name a few. It appears that R-C is using a larger framework that awards badges, points and whatnot for interaction on the site, and some of these features are not in use (everyone has the same negative birthday timestamp). In any case, this is terrible.
- Every article you load up fetches a file like this to return all comment objects.
2. some important sections are not https-enforced:
Register page : non-https and https are actually both valid. Same with the “user” page, which can be found https here or non-https here (with an added bonus, for whatever reason, you get the banner included on the non-http version!). I mean…how hard is it to disable port 80? I can only imagine all the nasty things you could do with ssl-strip!
3. Outdated tech stack?
Choosing technologies for your website is always difficult, but it seems like R-C settled on a combo of Microsoft’s IIS 7.5 and aspx pages. I’ve never used IIS myself but I have done asp programming, and I know it’s a goddamn mess. I work in the startup world, and I’ve never heard of anyone using IIS, but there might be a good reason for them to do so? Or maybe not, I don’t really know.
BONUS!
Javascript easter eggs!
Once in a while I click in the comments, open my dev console, close it (not sure) and I get this pop-up!
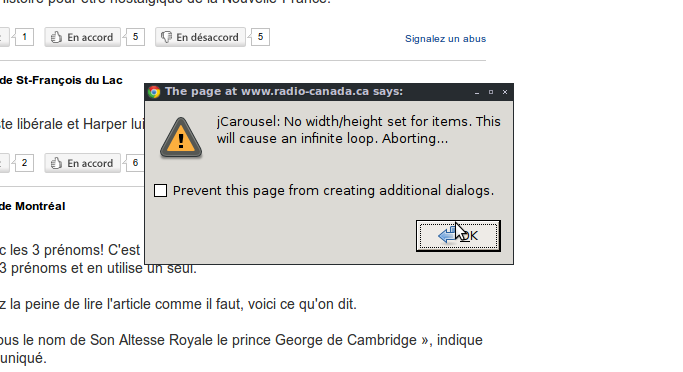
I’m pretty sure this feature has been there for a while, I just can’t figure out the correct combo. Help?
#2 CNAMED urls! : I was playing around checking what their hostnames were resolving to, and found my answer to complaint #1 (shitty URL), radio-canada.ca actually points to an IP which resolves to http://simondurivage.ca/ (an old R-C anchor)! They just need to start advertising this URL instead of radio-canada now! (no but seriously, WTF is going on???)